Wednesday, July 26, 2006
Baseline application accuracy
Yontem 1: num of exactly matching words < avg. number of exactly matching words for the specific task(SUM, QA, IE, IR)?
Yontem 2: std. dev. in the alignment of the matching words < avg. std. dev. for the specific task?
Yontem 3: dist. between first and last matching words < avg. dist for the specific task?
YONTEM 1 YONTEM 2 YONTEM 3
-------------------------------------------------------------------
SUM 108/200 (54%) 121/200(60%) 100/200(50%)
QA 99/200 (50%) 119/200(59%) 117/200(58%)
IE 103/200 (52%) 110/200(55%) 109/200(55%)
IR 106/200 (53%) 106/200(53%) 106/200(53%)
Yontem 2: std. dev. in the alignment of the matching words < avg. std. dev. for the specific task?
Yontem 3: dist. between first and last matching words < avg. dist for the specific task?
YONTEM 1 YONTEM 2 YONTEM 3
------------------------------
SUM 108/200 (54%) 121/200(60%) 100/200(50%)
QA 99/200 (50%) 119/200(59%) 117/200(58%)
IE 103/200 (52%) 110/200(55%) 109/200(55%)
IR 106/200 (53%) 106/200(53%) 106/200(53%)
Monday, July 24, 2006
Some basic queries about RTE 2 Dataset
loading RTE Dataset...
avg. number of tokens in text / hypothesis:
entailment: | NO YES all
task: |
--------------+--------------------------------------------------
SUM | 39.32 / 27.25 38.47 / 18.62 38.90 / 22.93
QA | 37.53 / 11.99 32.89 / 11.66 35.21 / 11.82
IR | 33.92 / 11.52 35.06 / 11.17 34.49 / 11.35
IE | 45.85 / 12.02 40.23 / 11.95 43.04 / 11.98
all | 39.16 / 15.70 36.66 / 13.35 37.91 / 14.52
avg. number of sentences in text / hypothesis:
entailment: | NO YES all
task: |
--------------+--------------------------------------------------
SUM | 1.02 / 1.00 1.00 / 1.00 1.01 / 1.00
QA | 1.23 / 1.00 1.09 / 1.00 1.16 / 1.00
IR | 1.05 / 1.00 1.08 / 1.00 1.06 / 1.00
IE | 1.06 / 1.01 1.05 / 1.00 1.05 / 1.00
all | 1.09 / 1.00 1.05 / 1.00 1.07 / 1.00
avg. number of tokens in a sentence of text / hypothesis:
entailment: | NO YES all
task: |
--------------+--------------------------------------------------
SUM | 38.55 / 27.25 38.47 / 18.62 38.90 / 22.93
QA | 30.51 / 11.99 30.17 / 11.66 35.21 / 11.82
IR | 32.30 / 11.52 32.46 / 11.17 34.49 / 11.35
IE | 43.25 / 11.90 38.31 / 11.95 40.80 / 11.93
all | 35.92 / 15.66 34.75 / 13.35 35.35 / 14.50
avg. number of exactly matching words in a pair:
entailment: | NO YES all
task: |
--------------+--------------------------------------
SUM | 8.57 9.57 9.07
QA | 6.70 7.10 6.90
IR | 3.95 4.53 4.24
IE | 6.59 6.21 6.40
all | 6.46 6.86 6.66
avg. standard deviation in the alignment of the exacly matching words in a pair (T-H):
EXAMPLE 1:
Text: u1 u2 x y z u6 u7 u8 u9 u10 u11 u12 u13 u 14 u15 u16
| | |
| | |
Hypothesis: v1 v2 v3 v4 x y z v8
[Perfectly aligned: StdDev = 0]
EXAMPLE 2:
Text: u1 u2 x u4 u5 u6 u7 u8 y u10 u11 u12 u13 z u15 u16
| | |
| | |
Hypothesis: v1 z v3 y v5 v6 x v8
[Not a good alignment:
number of shift for x = s_x = +4
number of shift for y = s_y = -5
number of shift for z = s_z = -12
number of exact matches = n = 3
mean shift = m = (4 - 5 - 12) / 3 = -7
stddev = sqrt (((m - s_x)^2 + (m - s_y)^2 + (m - s_z)^2) / n)
stddev = sqrt (((4 - 7)^2 + (-5 - 7)^2 + (-12 - 7)^2) / 3)
stddev = 13.08]
entailment: | NO YES all
task: |
--------------+-------------------------------------
SUM | 6.99 5.46 6.23
QA | 6.21 5.02 5.62
IR | 3.88 4.31 4.09
IE | 7.47 5.85 6.66
all | 6.15 5.16 5.65
avg. distance between the first and last exactly matching words in a text (T):
entailment: | NO YES all
task: |
--------------+--------------------------------
SUM | 19.96 19.52 19.74
QA | 17.72 14.38 16.05
IR | 10.20 12.06 11.13
IE | 20.78 16.31 18.55
all | 17.18 15.58 16.38
avg. distance between exactly matching words in a text (T):
entailment: | NO YES all
task: |
--------------+------------------------------
SUM | 2.11 1.77 1.94
QA | 2.36 1.70 2.03
IR | 1.89 2.09 1.99
IE | 2.91 2.25 2.58
all | 2.32 1.95 2.14
avg. number of tokens in text / hypothesis:
entailment: | NO YES all
task: |
--------------+--------------------------------------------------
SUM | 39.32 / 27.25 38.47 / 18.62 38.90 / 22.93
QA | 37.53 / 11.99 32.89 / 11.66 35.21 / 11.82
IR | 33.92 / 11.52 35.06 / 11.17 34.49 / 11.35
IE | 45.85 / 12.02 40.23 / 11.95 43.04 / 11.98
all | 39.16 / 15.70 36.66 / 13.35 37.91 / 14.52
avg. number of sentences in text / hypothesis:
entailment: | NO YES all
task: |
--------------+--------------------------------------------------
SUM | 1.02 / 1.00 1.00 / 1.00 1.01 / 1.00
QA | 1.23 / 1.00 1.09 / 1.00 1.16 / 1.00
IR | 1.05 / 1.00 1.08 / 1.00 1.06 / 1.00
IE | 1.06 / 1.01 1.05 / 1.00 1.05 / 1.00
all | 1.09 / 1.00 1.05 / 1.00 1.07 / 1.00
avg. number of tokens in a sentence of text / hypothesis:
entailment: | NO YES all
task: |
--------------+--------------------------------------------------
SUM | 38.55 / 27.25 38.47 / 18.62 38.90 / 22.93
QA | 30.51 / 11.99 30.17 / 11.66 35.21 / 11.82
IR | 32.30 / 11.52 32.46 / 11.17 34.49 / 11.35
IE | 43.25 / 11.90 38.31 / 11.95 40.80 / 11.93
all | 35.92 / 15.66 34.75 / 13.35 35.35 / 14.50
avg. number of exactly matching words in a pair:
entailment: | NO YES all
task: |
--------------+--------------------------------------
SUM | 8.57 9.57 9.07
QA | 6.70 7.10 6.90
IR | 3.95 4.53 4.24
IE | 6.59 6.21 6.40
all | 6.46 6.86 6.66
avg. standard deviation in the alignment of the exacly matching words in a pair (T-H):
EXAMPLE 1:
Text: u1 u2 x y z u6 u7 u8 u9 u10 u11 u12 u13 u 14 u15 u16
| | |
| | |
Hypothesis: v1 v2 v3 v4 x y z v8
[Perfectly aligned: StdDev = 0]
EXAMPLE 2:
Text: u1 u2 x u4 u5 u6 u7 u8 y u10 u11 u12 u13 z u15 u16
| | |
| | |
Hypothesis: v1 z v3 y v5 v6 x v8
[Not a good alignment:
number of shift for x = s_x = +4
number of shift for y = s_y = -5
number of shift for z = s_z = -12
number of exact matches = n = 3
mean shift = m = (4 - 5 - 12) / 3 = -7
stddev = sqrt (((m - s_x)^2 + (m - s_y)^2 + (m - s_z)^2) / n)
stddev = sqrt (((4 - 7)^2 + (-5 - 7)^2 + (-12 - 7)^2) / 3)
stddev = 13.08]
entailment: | NO YES all
task: |
--------------+-------------------------------------
SUM | 6.99 5.46 6.23
QA | 6.21 5.02 5.62
IR | 3.88 4.31 4.09
IE | 7.47 5.85 6.66
all | 6.15 5.16 5.65
avg. distance between the first and last exactly matching words in a text (T):
entailment: | NO YES all
task: |
--------------+--------------------------------
SUM | 19.96 19.52 19.74
QA | 17.72 14.38 16.05
IR | 10.20 12.06 11.13
IE | 20.78 16.31 18.55
all | 17.18 15.58 16.38
avg. distance between exactly matching words in a text (T):
entailment: | NO YES all
task: |
--------------+------------------------------
SUM | 2.11 1.77 1.94
QA | 2.36 1.70 2.03
IR | 1.89 2.09 1.99
IE | 2.91 2.25 2.58
all | 2.32 1.95 2.14
Sunday, July 23, 2006
#8 (from RTE 1) Summary
- Probabilistic approach
- They do lexical entailment based on web co-occurrence statistics in a bag of words representation.
- It does not rely on syntactic or other deeper analysis.
Suppose:
h1 = "Harry was born in Iowa.",
t1 includes "Harry's birthplace is Iowa.", and
t2 includes "Harry is returning to his Iowa hometown to get married."
P(h1 is TRUE | t1) ought to be much higher than P(h1 is TRUE | t2).
More specifically, we might say that the probability p of h1 being true should be estimated based on the percentage of cases in which someone's reported hometown is indeed his/her birthplace. And t2 would not be accepted as a definite assessment for the truth of h1.
However, in the absence of other definite information, t2 may partly satisfy the information
need for an assessment of the probable truth of h1, with p providing a confidence probability for this inference.
A Probabilistic Setting
Let t denote a possible text, and
let h denote a possible hypothesis.
t is in T (space of possible texts)
h is in H(space of all possible hypothesis)
let source be the thing that generates text t.
Meanings are captured by hypothesis and their truth values.
A hypothesis h in H is a propositional statement that can be assigned a truth value.
a possible world is:
from (1) and (2), the entailment probability is estimated as:
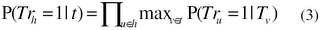
Web-based Estimation of P(Tr_u = 1 | T_v):
Given that the possible world of the text is not observed we do not know the truth assignments of hypotheses for the observed texts. We therefore further make the simplest assumption that all hypotheses stated verbatim in a document are true and all others are false and hence:
P(Tr_u = 1 | T_v) = P(T_u | T_v) = lep (u, v)
[lep: lexical entialment probability]
lep is estimated based on maximum likelihood counts:
lep(u,v) is proportional to (n_uv / n_v)
[n_v: number of documents containing v,
n_uv: number of documents containing both u and v]

If this value is greater than a empirically tuned threshold k, the entailment holds.
accuracy = 59%
cws = 0.57
- They do lexical entailment based on web co-occurrence statistics in a bag of words representation.
- It does not rely on syntactic or other deeper analysis.
Suppose:
h1 = "Harry was born in Iowa.",
t1 includes "Harry's birthplace is Iowa.", and
t2 includes "Harry is returning to his Iowa hometown to get married."
P(h1 is TRUE | t1) ought to be much higher than P(h1 is TRUE | t2).
More specifically, we might say that the probability p of h1 being true should be estimated based on the percentage of cases in which someone's reported hometown is indeed his/her birthplace. And t2 would not be accepted as a definite assessment for the truth of h1.
However, in the absence of other definite information, t2 may partly satisfy the information
need for an assessment of the probable truth of h1, with p providing a confidence probability for this inference.
A Probabilistic Setting
Let t denote a possible text, and
let h denote a possible hypothesis.
t is in T (space of possible texts)
h is in H(space of all possible hypothesis)
let source be the thing that generates text t.
Meanings are captured by hypothesis and their truth values.
A hypothesis h in H is a propositional statement that can be assigned a truth value.
a possible world is:
w: H -> {0:false, 1:true}
It represents the set of w's concrete truth value assignments for all possible propositions.
Whenever the source generates a text t, it generates also hidden truth assignments that constitute a possible world w. (The hidden w is perceived as a "snapshot" of the (complete) state of affairs in the world within which t was generated.)
The probability distribution of the source, over all possible texts and truth assignments T × W, is assumed to reflect only inferences that are based on the generated texts.
That is, it is assumed that the distribution of truth assignments is not bound to reflect the state of affairs in any "real" world, but only the inferences about propositions' truth that are related to the text.
In particular, the probability for generating a true hypothesis h that is not related at all to the corresponding text is determined by some prior probability P(h), which is not bound to reflect h's prior in the "real" world.
EX:
h="Paris is the capital of France" might well be false when the generated text is not related at all to Paris.
1) For a hypothesis h, we denote as Tr_h the random variable whose value is the truth value assigned to h in the world of the generated text. Correspondingly, Tr_h=1 is the event of h being assigned a truth value of 1 (True).
2) For a text t, we use t to denote also the event that the generated text is t (as usual, it is clear from the context whether t denotes the text or the corresponding event).
We say that t probabilistically entails h (denoted as t->h) if t increases the likelihood of h being true, that is, if P(Tr_h = 1| t) > P(Tr_h = 1)
The probabilistic confidence value corresponds to P(Tr_h = 1| t).
We assume that the meanings of the individual (content) words in a hypothesis h={u_1, …, u_m} can be assigned truth values. We only assume that truth values are defined for lexical items, but do not explicitly annotate or evaluate this sub-task.
Given this setting, a hypothesis is assumed to be true if and only if all its lexical components are
Whenever the source generates a text t, it generates also hidden truth assignments that constitute a possible world w. (The hidden w is perceived as a "snapshot" of the (complete) state of affairs in the world within which t was generated.)
The probability distribution of the source, over all possible texts and truth assignments T × W, is assumed to reflect only inferences that are based on the generated texts.
That is, it is assumed that the distribution of truth assignments is not bound to reflect the state of affairs in any "real" world, but only the inferences about propositions' truth that are related to the text.
In particular, the probability for generating a true hypothesis h that is not related at all to the corresponding text is determined by some prior probability P(h), which is not bound to reflect h's prior in the "real" world.
EX:
h="Paris is the capital of France" might well be false when the generated text is not related at all to Paris.
1) For a hypothesis h, we denote as Tr_h the random variable whose value is the truth value assigned to h in the world of the generated text. Correspondingly, Tr_h=1 is the event of h being assigned a truth value of 1 (True).
2) For a text t, we use t to denote also the event that the generated text is t (as usual, it is clear from the context whether t denotes the text or the corresponding event).
We say that t probabilistically entails h (denoted as t->h) if t increases the likelihood of h being true, that is, if P(Tr_h = 1| t) > P(Tr_h = 1)
The probabilistic confidence value corresponds to P(Tr_h = 1| t).
We assume that the meanings of the individual (content) words in a hypothesis h={u_1, …, u_m} can be assigned truth values. We only assume that truth values are defined for lexical items, but do not explicitly annotate or evaluate this sub-task.
Given this setting, a hypothesis is assumed to be true if and only if all its lexical components are
true.
We assume that the truth probability of a term in a hypothesis h is independent of the truth of the other terms in h:
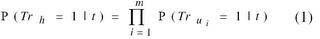
We assume that the truth probability of a term in a hypothesis h is independent of the truth of the other terms in h:
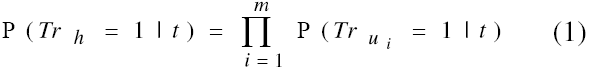
For a given word u, to estimate P(Tr_u = 1 | t), where t = {v_1, ..., v_n}, we further assume that the majority of the probability mass comes from a specific entailing word in t:
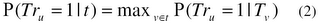
where T_v denotes the event that a generated text contains the words v.
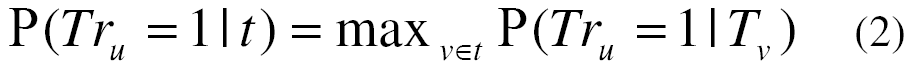
where T_v denotes the event that a generated text contains the words v.
from (1) and (2), the entailment probability is estimated as:
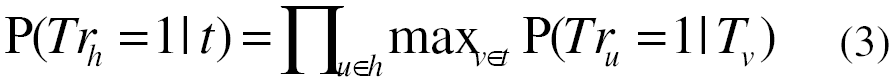
Web-based Estimation of P(Tr_u = 1 | T_v):
Given that the possible world of the text is not observed we do not know the truth assignments of hypotheses for the observed texts. We therefore further make the simplest assumption that all hypotheses stated verbatim in a document are true and all others are false and hence:
P(Tr_u = 1 | T_v) = P(T_u | T_v) = lep (u, v)
[lep: lexical entialment probability]
lep is estimated based on maximum likelihood counts:
lep(u,v) is proportional to (n_uv / n_v)
[n_v: number of documents containing v,
n_uv: number of documents containing both u and v]
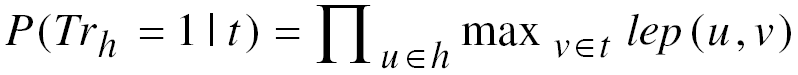
If this value is greater than a empirically tuned threshold k, the entailment holds.
accuracy = 59%
cws = 0.57
Saturday, July 22, 2006
RTE 2 Dataset icin Parser yazdim (Python'da)
Artik RTE 2 dataset'ini parse edebiliyoruz:
Yani elimizde her bir T-H (Text-Hypothesis) ikilisi icin:
(raw data)
THPair:
- id
- entailment: TRUE/FALSE
- task: QA/SUM/IE/IR
- text: "... ... ... ... .."
- hypothesis: ".. .. ..."
veya
(preprocessed data)
XTHPair:
-id
- entailment: TRUE/FALSE
- task: QA/SUM/IE/IR
- text:
XSentence:
- serial (in other words index within the context)
- nodes:
XNode:
- id (unique within the sentence)
- word
- lemma
- pos
- relation:
Relation'daki 'parent node', cumleleri bir parse tree seklinde ifade edebilmemizi sagliyor.
Yani elimizde her bir T-H (Text-Hypothesis) ikilisi icin:
(raw data)
THPair:
- id
- entailment: TRUE/FALSE
- task: QA/SUM/IE/IR
- text: "... ... ... ... .."
- hypothesis: ".. .. ..."
veya
(preprocessed data)
XTHPair:
-id
- entailment: TRUE/FALSE
- task: QA/SUM/IE/IR
- text:
- XSentence
- XSentence
- XSentence
- XSentence
XSentence:
- serial (in other words index within the context)
- nodes:
- XNode (in other words, atomic tokens in the sentence)
- XNode
- XNode
- ...
- XNode
XNode:
- id (unique within the sentence)
- word
- lemma
- pos
- relation:
- relation type
- parent XNode
Relation'daki 'parent node', cumleleri bir parse tree seklinde ifade edebilmemizi sagliyor.
#8 Web Based Probabilistic Textual Entailment (from RTE 1)
Abstract
This paper proposes a general probabilistic
setting that formalizes the notion of
textual entailment. In addition we describe
a concrete model for lexical entailment
based on web co-occurrence
statistics in a bag of words representation.
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/glickman_et_al.pdf
This paper proposes a general probabilistic
setting that formalizes the notion of
textual entailment. In addition we describe
a concrete model for lexical entailment
based on web co-occurrence
statistics in a bag of words representation.
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/glickman_et_al.pdf
Thursday, July 20, 2006
#13 (from RTE 1) Summary
- T and H are seen as two syntactic graphs to reduce the textual entailment
- In principle, textual entailment is a transitive oriented relation holding in one these:
- H is supposed to be a sentence describing completely a fact in an assertive or negative way
- H should be a simple subject-verb-object sentence
Measure:
- E(XDG(T), XDG(H)), where XDG(T) and XDG(H) are syntactic representation of T and H as eXtended Dependancy Graph.
- E(XDG(T), XDG(H)) has to satisfy:
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/zanzotto_et_al.pdf
- In principle, textual entailment is a transitive oriented relation holding in one these:
- T semantically subsumes H (e.g. H: The cat eats the mouse, T: the devours the mouse) eat generalizes devour
- T syntactically subsumes H (e.g. H: The cat eats the mouse, T: the cat eats the mouse in the garden)
- T directly implies H (e.g. H: The cat killed the mouse, T: the cat devours the mouse)
- H is supposed to be a sentence describing completely a fact in an assertive or negative way
- H should be a simple subject-verb-object sentence
Measure:
- E(XDG(T), XDG(H)), where XDG(T) and XDG(H) are syntactic representation of T and H as eXtended Dependancy Graph.
- E(XDG(T), XDG(H)) has to satisfy:
- E(XDG(T), XDG(H)) not equals E(XDG(H), XDG(T))
- the overlap between XDG(T) and XDG(H) has to describe if a subgraph of XDG(T) implies the graph XDG(H)
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/zanzotto_et_al.pdf
#13 Textual Entailment as Syntactic Graph Distance: a rule based and a SVM based approach (from RTE 1)
Abstract
In this paper we define a measure for textual
entailment recognition based on the
graph matching theory applied to syntactic
graphs. We describe the experiments
carried out to estimate measure’s parameters
with SVM and we report the results
obtained on the Textual Entailment Challenge
development and testing set.
The paper: http://www.cs.biu.ac.il/~glikmao/rte05/zanzotto_et_al.pdf
In this paper we define a measure for textual
entailment recognition based on the
graph matching theory applied to syntactic
graphs. We describe the experiments
carried out to estimate measure’s parameters
with SVM and we report the results
obtained on the Textual Entailment Challenge
development and testing set.
The paper: http://www.cs.biu.ac.il/~glikmao/rte05/zanzotto_et_al.pdf
#7 (from RTE 1) Summary
System transforms each T-H pair into logic form representaion with semantic relations
System automatically generates:
- NLP axioms serving as linguistic rewriting rules
- lexical chain axioms that connect concepts in T and H
COGEX logic prover(modified version of OTTER) is used to prove entailments using:
- semantic relations,
- WordNet lexical chains
- NLP axioms
The hypothesis is negated, and if it contradicts anything in T or anything inferred from T, return TRUE.
System Description:
- convert T and H into logic forms (Moldovan and Rus, 2001), which includes:
- a list of cluases called the "set of support"
They provide external world knowledge:
- a small common-sense knowledge base of 310 world knowledge axioms:
- linguistic rewriting rules that help break down complex logic structures and express syntactic equivalence.
- automatically generated by the system through logic form and parse tree analysis.
- generated to break down complex nominals and coordinating conjunctions into their components so that other axioms can be applied to the components individually to generate a larger set of inferences.
- other axioms help:
- WordNet provides links between synsets
- Each synset has a set of corresponding predicates for each word in the synonym set.
- predicate name is formed by synonym word form, pos, sense id
- predicates corresponding to noun synsets usually have a single argument
- predicates corresponding to verb synset three: event, subject, object
- A lexical chain is a chain of relations between two synsets.
- System prouces axioms using the predicates corresponding to the synsets in the relation.
EX:
buy_VB_1 (e1, x1, x2) -> pay_VB_1 (e1, x1, x3) (neden x3 ama x2 degil?)
- The following three classes of relations are used:
- sort the "support list" in the order of weights
- drop the axioms with small weights
- seach the "usable list" for new inferences that can be made
- any inferences produced are assigned an appropriate weight depending on the axioms it is derived from
- continue until support list is empty
- if a refutation is found, return TRUE
- else relax the predicate arguments.
- if a refutation is found, return TRUE
- else drop predicates from the negated hypothesis until a refutation is found.
- earlier a refutation found, higher the confidence weight
accuracy: between 0.5 and 0.7
cws: between 0.4 and 0.6
The Paper: www.cs.biu.ac.il/~glikmao/rte05/fowler_et_al.pdf
System automatically generates:
- NLP axioms serving as linguistic rewriting rules
- lexical chain axioms that connect concepts in T and H
COGEX logic prover(modified version of OTTER) is used to prove entailments using:
- semantic relations,
- WordNet lexical chains
- NLP axioms
The hypothesis is negated, and if it contradicts anything in T or anything inferred from T, return TRUE.
System Description:
- convert T and H into logic forms (Moldovan and Rus, 2001), which includes:
- pos tagging
- parse tree generation
- WSD (removed because of the inaccuracy)
- semantic relation detection
- a list of cluases called the "set of support"
- negated form of H
- predicated that make up T
They provide external world knowledge:
- knowledge of syntactic equivalence between logic form predicates, and
- lexical knowledge in the form of lexical chains.
- a small common-sense knowledge base of 310 world knowledge axioms:
- 80 manually designed (based on development data)
- 230 from previous projects
- linguistic rewriting rules that help break down complex logic structures and express syntactic equivalence.
- automatically generated by the system through logic form and parse tree analysis.
- generated to break down complex nominals and coordinating conjunctions into their components so that other axioms can be applied to the components individually to generate a larger set of inferences.
- other axioms help:
- establish equivalence between prepositions
- establish equivalence between different POS
- equate words that have multiple noun forms
- equate substantives within appositions
- WordNet provides links between synsets
- Each synset has a set of corresponding predicates for each word in the synonym set.
- predicate name is formed by synonym word form, pos, sense id
- predicates corresponding to noun synsets usually have a single argument
- predicates corresponding to verb synset three: event, subject, object
- A lexical chain is a chain of relations between two synsets.
- System prouces axioms using the predicates corresponding to the synsets in the relation.
EX:
buy_VB_1 (e1, x1, x2) -> pay_VB_1 (e1, x1, x3) (neden x3 ama x2 degil?)
- The following three classes of relations are used:
- pure WordNet relations
- generated from WordNet derivational morphology
- generated from WordNet glosses
- sort the "support list" in the order of weights
- drop the axioms with small weights
- seach the "usable list" for new inferences that can be made
- any inferences produced are assigned an appropriate weight depending on the axioms it is derived from
- continue until support list is empty
- if a refutation is found, return TRUE
- else relax the predicate arguments.
- if a refutation is found, return TRUE
- else drop predicates from the negated hypothesis until a refutation is found.
- earlier a refutation found, higher the confidence weight
accuracy: between 0.5 and 0.7
cws: between 0.4 and 0.6
The Paper: www.cs.biu.ac.il/~glikmao/rte05/fowler_et_al.pdf
#7 Applying COGEX to Recognize Textual Entailment (from RTE 1)
Abstract
The PASCAL RTE challenge has helped
LCC to explore the applicability of enhancements
that have been made to our
logic form representation and WordNet
lexical chains generator. Our system
transforms each T-H pair into logic form
representation with semantic relations.
The system automatically generates NLP
axioms serving as linguistic rewriting
rules and lexical chain axioms that connect
concepts in the hypothesis and text.
A light set of simple hand-coded world
knowledge axioms are also included. Our
COGEX logic prover is then used to attempt
to prove entailment. Semantic relations,
WordNet lexical chains, and NLP
axioms all helped the logic prover detect
entailment.
The Paper: www.cs.biu.ac.il/~glikmao/rte05/fowler_et_al.pdf
The PASCAL RTE challenge has helped
LCC to explore the applicability of enhancements
that have been made to our
logic form representation and WordNet
lexical chains generator. Our system
transforms each T-H pair into logic form
representation with semantic relations.
The system automatically generates NLP
axioms serving as linguistic rewriting
rules and lexical chain axioms that connect
concepts in the hypothesis and text.
A light set of simple hand-coded world
knowledge axioms are also included. Our
COGEX logic prover is then used to attempt
to prove entailment. Semantic relations,
WordNet lexical chains, and NLP
axioms all helped the logic prover detect
entailment.
The Paper: www.cs.biu.ac.il/~glikmao/rte05/fowler_et_al.pdf
Wednesday, July 19, 2006
#4 (from RTE 1) Summary
2 farkli sistem kullanarak yarismaya katildilar:
System 1:
- The system processes both H and T using:
- Total pairs processed: 800
- Corrected labeled T: 11/285 and F:292/302 accuracy:0.52 cws:0.5
System 2:
The system is inspired by Statistical machine translation models.
- Machine Translation (MT) evaluation
- some string matching algorithms (Gusfield, 1997)
- MT alignment score
ORNEK: (GIZA++ alignment for a training pair)
T: Floods caused by Monday's torrential rains surrounded two villages in the southern part of
.......|.............................................................. |........... |...... |.......|........... |................
H: Floods............................................................ engulf .. two villages in southern..............
T: Bushehr province today ...
........|................................
H: Iran.............................
(blogspot'ta arka arkaya bosluk koyulamiyor, o yuzden nokta kullandim)
Development set yetersiz oldugu icin Gigaword newswire corpus (Graff, 2003) 'dan yararlanilmis.
Hipotezlerine gore: Bir haberin ilk paragrafindan(lead) haberin basligi(headline) entail edilebiliyor.
Hipotezlerini test etmek icin:
- 1000 tane lead-headline manually judge ediliyor.
- Buna gore Gigaword'un %60 'i icin bu hipotezin dogru oldugu tahmin ediliyor.
- (SVMlight: Joachims, 2002) kullanilarak bu data refine ediliyor. "Like those classifiers used to predict genre or topic, this training included the entire articles with bag-of-words features."
- Finally, they derive a 100,000-document subset of Gigaword with approximately 75% lead-entails-headline purity.
Fakat training data neredeyse ise yaramiyor. Cunku RTE 'deki negative instance'larda T ve H arasinda substantial conceptual overlap varken, negative Gigaword pair'larinda overlap cok az var.
Paper RTE dataset'i elestiriyor. Kendi human judger'lari ile RTE annotator'lari arasinda entailment'larda hemfikirlilik orani 91%.
Sunu farketmisler ki: TRUE entailment'larin 94%'u sadece basit paraphrase'ler:
ORNEK:
John murdered Bill -> Bill was killed by John. (as opposed to classic entailments (Bill is dead).
"During this process, we uncovered many ceases where we disagreed with the given truth value on the grounds of synonymy (in bloody clothes -> covered in blood)"
"We also identified potential disagreements
about the extent to which world knowledge is allowed
to play a role. For instance, pair 102 (domestic
threat threat of attack) is more
convincing if one understands the implications of
al Qaeda and September 11, 2001 mentioned in the
text."
(Dataset'ler download edilemiyor, dataset'leri host eden arkadasa email attim, Mail Delivery System'den failure geliyor.)
Score:
- Total pairs processed: 800
- Corrected Labeled T: 231/400 F:238/400 accuracy: 0.59 precision:0.59 cws:0.62
The paper: http://www.cs.biu.ac.il/~glikmao/rte05/bayer_et_al.pdf
System 1:
- The system processes both H and T using:
- MITRE-built tokenizer
- sentence segmenter
- the Ratnaparkhi (1996) POS tagger
- the University of Sussex's Morph morphological analyzer
- the CMU Link Grammar parser
- a MITRE-built dependency analyzer
- Davidsonian logic generator
- the Uniersity of Rochester's EPILOG event-oriented probabilistic inference engine
- Total pairs processed: 800
- Corrected labeled T: 11/285 and F:292/302 accuracy:0.52 cws:0.5
System 2:
The system is inspired by Statistical machine translation models.
- Machine Translation (MT) evaluation
- some string matching algorithms (Gusfield, 1997)
- MT alignment score
ORNEK: (GIZA++ alignment for a training pair)
T: Floods caused by Monday's torrential rains surrounded two villages in the southern part of
.......|.............................................................. |........... |...... |.......|........... |................
H: Floods............................................................ engulf .. two villages in southern..............
T: Bushehr province today ...
........|................................
H: Iran.............................
(blogspot'ta arka arkaya bosluk koyulamiyor, o yuzden nokta kullandim)
Development set yetersiz oldugu icin Gigaword newswire corpus (Graff, 2003) 'dan yararlanilmis.
Hipotezlerine gore: Bir haberin ilk paragrafindan(lead) haberin basligi(headline) entail edilebiliyor.
Hipotezlerini test etmek icin:
- 1000 tane lead-headline manually judge ediliyor.
- Buna gore Gigaword'un %60 'i icin bu hipotezin dogru oldugu tahmin ediliyor.
- (SVMlight: Joachims, 2002) kullanilarak bu data refine ediliyor. "Like those classifiers used to predict genre or topic, this training included the entire articles with bag-of-words features."
- Finally, they derive a 100,000-document subset of Gigaword with approximately 75% lead-entails-headline purity.
Fakat training data neredeyse ise yaramiyor. Cunku RTE 'deki negative instance'larda T ve H arasinda substantial conceptual overlap varken, negative Gigaword pair'larinda overlap cok az var.
Paper RTE dataset'i elestiriyor. Kendi human judger'lari ile RTE annotator'lari arasinda entailment'larda hemfikirlilik orani 91%.
Sunu farketmisler ki: TRUE entailment'larin 94%'u sadece basit paraphrase'ler:
ORNEK:
John murdered Bill -> Bill was killed by John. (as opposed to classic entailments (Bill is dead).
"During this process, we uncovered many ceases where we disagreed with the given truth value on the grounds of synonymy (in bloody clothes -> covered in blood)"
"We also identified potential disagreements
about the extent to which world knowledge is allowed
to play a role. For instance, pair 102 (domestic
threat threat of attack) is more
convincing if one understands the implications of
al Qaeda and September 11, 2001 mentioned in the
text."
(Dataset'ler download edilemiyor, dataset'leri host eden arkadasa email attim, Mail Delivery System'den failure geliyor.)
Score:
- Total pairs processed: 800
- Corrected Labeled T: 231/400 F:238/400 accuracy: 0.59 precision:0.59 cws:0.62
The paper: http://www.cs.biu.ac.il/~glikmao/rte05/bayer_et_al.pdf
#4 MITRE’s Submissions to the EU Pascal RTE Challenge (from RTE 1)
Abstract
We describe MITRE’s two submissions to
the RTE Challenge, intended to exemplify
two different ends of the spectrum of possibilities.
The first submission is a traditional
system based on linguistic analysis
and inference, while the second is inspired
by alignment approaches from machine
translation. We also describe our
efforts to build our own entailment corpus.
Finally, we discuss our investigations
and reflections on the strengths and
weaknesses of the evaluation itself.
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/bayer_et_al.pdf
We describe MITRE’s two submissions to
the RTE Challenge, intended to exemplify
two different ends of the spectrum of possibilities.
The first submission is a traditional
system based on linguistic analysis
and inference, while the second is inspired
by alignment approaches from machine
translation. We also describe our
efforts to build our own entailment corpus.
Finally, we discuss our investigations
and reflections on the strengths and
weaknesses of the evaluation itself.
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/bayer_et_al.pdf
#3 (from RTE 1) Summary
CLaC PASCAL Algorithm:
- Use the coreference resolution system to produce coreference chains for T, H, T and H as a unit.
- For each sentence, determine Predicate-Argument-Structures (PAS), based on the parsing, NP chunking and verb grouping results.
- Apply cardinality filter (if there exists a numeric value N in H that does not exist in T, return false)
- Convert passive voices into active voices.
- For each PAS pair, compute WN distance for verbs in T and H
If WN distance <= threshold & both PASs are in comparable structures, and If there is coreference between corresponding parts, return true - Apply Be-Heuristic Algorithm if H contains the pattern "X is Y", and
(X is in H) & (X' is in T) and {X, X'} belong to the same inter-sentence coreference chain, and
(Y is in H) & (Y' is in T) and {Y, Y'} belong to the same inter-sentence coreference chain, and
X' corefers with Y'
then return true
return false
Precision: around 0.5
Recall: around 0.2
Accuracy: around 0.55
Confidence-Weighted Score (cws): around 0.55
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/andreevskaia_et_al.pdf
- Use the coreference resolution system to produce coreference chains for T, H, T and H as a unit.
- For each sentence, determine Predicate-Argument-Structures (PAS), based on the parsing, NP chunking and verb grouping results.
- Apply cardinality filter (if there exists a numeric value N in H that does not exist in T, return false)
- Convert passive voices into active voices.
- For each PAS pair, compute WN distance for verbs in T and H
If WN distance <= threshold & both PASs are in comparable structures, and If there is coreference between corresponding parts, return true - Apply Be-Heuristic Algorithm if H contains the pattern "X is Y", and
(X is in H) & (X' is in T) and {X, X'} belong to the same inter-sentence coreference chain, and
(Y is in H) & (Y' is in T) and {Y, Y'} belong to the same inter-sentence coreference chain, and
X' corefers with Y'
then return true
return false
Precision: around 0.5
Recall: around 0.2
Accuracy: around 0.55
Confidence-Weighted Score (cws): around 0.55
The Paper: http://www.cs.biu.ac.il/~glikmao/rte05/andreevskaia_et_al.pdf
#3 Can Shallow Predicate Argument Structures Determine? (from RTE 1)
Abstract
The CLaC Lab’s system for the PASCAL
RTE challenge explores the potential
of simple general heuristics and
a knowledge-poor approach for recognising
paraphrases, using NP coreference,
NP chunking, and two parsers
(RASP and Link) to produce Predicate
Argument Structures (PAS) for each of
the pair components. WordNet lexical
chains and a few specialised heuristics
are used to establish semantic similarity
between corresponding components
of the PAS from the pair. We discuss
the results and potential of this
approach.
The CLaC Lab’s system for the PASCAL
RTE challenge explores the potential
of simple general heuristics and
a knowledge-poor approach for recognising
paraphrases, using NP coreference,
NP chunking, and two parsers
(RASP and Link) to produce Predicate
Argument Structures (PAS) for each of
the pair components. WordNet lexical
chains and a few specialised heuristics
are used to establish semantic similarity
between corresponding components
of the PAS from the pair. We discuss
the results and potential of this
approach.
GATE - General Architecture for Text Engineering
GATE is made up of three elements:
- An architecture describing how language processing systems are made up of components.
- A framework (or class library, or SDK), written in Java and tested on Linux, Windows and Solaris.
- A graphical development environment built on the framework.
#2 (from RTE 1) Summary
http://www.cs.biu.ac.il/~glikmao/rte05/akhmatova.pdf
Kullanilan kaynaklar:
Text (T) ve Hypothesis (H) 'te proposition'lar detect ediliyor. Eger H'teki her bir proposition icin T'de bir matching proposition var ise, T entails H.
- Asagidaki sekilde logical formlar kullaniyorlar:
3 tip object var: Subj(x), Obj(x), Pred(x)
and a meaning attaching element: iq(x,)
ORNEK:
"Somali capital" -- Subj(x) & iq(x, 'capital') & attr(x, y) & Subj(y) & iq(y, 'somali')
"a zoo in Berlin" -- Obj(x) & iq(x, 'zoo') & prep(x, y) & Obj(y) & iq(y, 'Berlin')
- Wordnet 'teki relation'lardan logic formula'lar generate ediyorlar.
ORNEK:
Semantic synonymy is expressed as an equivalence:
Kullanilan kaynaklar:
- Wordnet
- Link Parser
- OTTER
- first-order logic forms
- Wordnet Relatedness Algorithm
Text (T) ve Hypothesis (H) 'te proposition'lar detect ediliyor. Eger H'teki her bir proposition icin T'de bir matching proposition var ise, T entails H.
- Asagidaki sekilde logical formlar kullaniyorlar:
3 tip object var: Subj(x), Obj(x), Pred(x)
and a meaning attaching element: iq(x,
ORNEK:
"a zoo in Berlin" -- Obj(x) & iq(x, 'zoo') & prep(x, y) & Obj(y) & iq(y, 'Berlin')
- Wordnet 'teki relation'lardan logic formula'lar generate ediyorlar.
ORNEK:
Semantic synonymy is expressed as an equivalence:
iq(x, 'serve') <-> iq(x, 'dish')
and hypernymy as:
iq(x, 'serve') -> iq(x, 'provide')
- Bazi lexical relation rule'lari store ediyorlar:
ORNEK:
- Bazi lexical relation rule'lari store ediyorlar:
ORNEK:
Ax (iq(x, 'is') <-> iq(x, 'be'))
- They describe syntactical equivalence by means of additional logic rules:
is
A y z z1 y77 z77 ((Pred(z1) & iq(z1, 'be') & Obj(y) & iq(y, y77) & prep(y, z) & Obj(z) & iq(z, z77))))
WordNet Relatedness:
- Iki kelime arasindaki path ne kadar uzun ise relatedness o kadar azaliyor.
- Path icerisindeki kelimelerin sense'leri ne kadar az ise, o kadar relatedness artiyor. (two words connected with a verb print are more close to each other, than the words connected via make; print has 4 senses, make has 49)
- Iki sense arasinda ne kadar cok farkli path varsa o kadar related.
ORNEK:
provide -- give (verb chain)
1. provide#1(7)[2259805] -- hyperonym -- give#3(44)[2136207]
...
7. provide#6(7)[2155855] -- hyperonym -- support#2(11)[2155507] -- hyperonym -- give#3(44)[2136207]
maximum path length -- 3
relatedness score: 0.3623 => Ax (iq(x, 'provide') -> iq(x, 'give'))
Bir T-H pair icin ORNEK:
T: Coffee boosts energy and proveides health benefits.
H: Coffee gives health benefits.
Propositions for T:
- Coffee boosts energy.
- Coffee provides health benefits.
Proposition for H:
- Coffee gives health benefits.
H'teki butun proposition'lar T'deki proposition'lardan bir tanesi ile match etmesi gerekiyor.
for (Coffee gives health benefits)
[FALSE]Coffee boosts energy => Coffee gives health benefits (FALSE)
[TRUE]Coffee provides health benefits => Coffee gives health benefits, as provides => gives, coffee = coffee, health benefits = health benefits
Performance of the System:
accuracy / cws = 0.5067 / 0.5188
"Be X of Y -> X Y" kullanarak verilen dogru cevaplara ORNEK:
T: The man is a director of the company
H: The man rules the company.
Yanlis cevablara ORNEK:
T: The man came to the park by car.
H: The man came to a car park.
- They describe syntactical equivalence by means of additional logic rules:
ORNEK:
"Be X of Y -> X Y" (director of the firm -> direct a firm)is
A y z z1 y77 z77 ((Pred(z1) & iq(z1, 'be') & Obj(y) & iq(y, y77) & prep(y, z) & Obj(z) & iq(z, z77))))
WordNet Relatedness:
- Iki kelime arasindaki path ne kadar uzun ise relatedness o kadar azaliyor.
- Path icerisindeki kelimelerin sense'leri ne kadar az ise, o kadar relatedness artiyor. (two words connected with a verb print are more close to each other, than the words connected via make; print has 4 senses, make has 49)
- Iki sense arasinda ne kadar cok farkli path varsa o kadar related.
ORNEK:
provide -- give (verb chain)
1. provide#1(7)[2259805] -- hyperonym -- give#3(44)[2136207]
...
7. provide#6(7)[2155855] -- hyperonym -- support#2(11)[2155507] -- hyperonym -- give#3(44)[2136207]
maximum path length -- 3
relatedness score: 0.3623 => Ax (iq(x, 'provide') -> iq(x, 'give'))
Bir T-H pair icin ORNEK:
T: Coffee boosts energy and proveides health benefits.
H: Coffee gives health benefits.
Propositions for T:
- Coffee boosts energy.
- Coffee provides health benefits.
Proposition for H:
- Coffee gives health benefits.
H'teki butun proposition'lar T'deki proposition'lardan bir tanesi ile match etmesi gerekiyor.
for (Coffee gives health benefits)
[FALSE]Coffee boosts energy => Coffee gives health benefits (FALSE)
[TRUE]Coffee provides health benefits => Coffee gives health benefits, as provides => gives, coffee = coffee, health benefits = health benefits
Performance of the System:
accuracy / cws = 0.5067 / 0.5188
"Be X of Y -> X Y" kullanarak verilen dogru cevaplara ORNEK:
T: The man is a director of the company
H: The man rules the company.
Yanlis cevablara ORNEK:
T: The man came to the park by car.
H: The man came to a car park.
#2 Textual Entailment Resolution via Atomic Propositions (from RTE 1)
http://www.cs.biu.ac.il/~glikmao/rte05/akhmatova.pdf
Abstract
This paper presents an approach to solving
the problem of textual entailment
recognition and describes the computer
application built to demonstrate the
performance of the proposed approach.
The method presented here is based on
syntax-driven semantic analysis and uses
the notion of atomic proposition as its
main element for entailment recognition.
The idea is to find the entailment relation
in the sentence pairs by comparing the
atomic propositions contained in the text
and hypothesis sentences.
The comparison of atomic propositions is
performed via an automated deduction
system OTTER; the propositions are
extracted from the output of the Link
Parser; and semantic knowledge is taken
from the WordNet database. On its current
stage the system is capable to recognize
basic semantically and syntactically based
entailments and is potentially capable to
use more external and internal knowledge
to deal with more complex entailments.
Abstract
This paper presents an approach to solving
the problem of textual entailment
recognition and describes the computer
application built to demonstrate the
performance of the proposed approach.
The method presented here is based on
syntax-driven semantic analysis and uses
the notion of atomic proposition as its
main element for entailment recognition.
The idea is to find the entailment relation
in the sentence pairs by comparing the
atomic propositions contained in the text
and hypothesis sentences.
The comparison of atomic propositions is
performed via an automated deduction
system OTTER; the propositions are
extracted from the output of the Link
Parser; and semantic knowledge is taken
from the WordNet database. On its current
stage the system is capable to recognize
basic semantically and syntactically based
entailments and is potentially capable to
use more external and internal knowledge
to deal with more complex entailments.
First-Order Logic (Lecture Notes)
- Every gardener likes the sun.
(Ax) gardener(x) => likes(x,Sun) - You can fool some of the people all of the time.
(Ex) (person(x) ^ (At)(time(t) => can-fool(x,t))) - You can fool all of the people some of the time.
(Ax) (person(x) => (Et) (time(t) ^ can-fool(x,t))) - All purple mushrooms are poisonous.
(Ax) (mushroom(x) ^ purple(x)) => poisonous(x) - No purple mushroom is poisonous.
~(Ex) purple(x) ^ mushroom(x) ^ poisonous(x)
or, equivalently,
(Ax) (mushroom(x) ^ purple(x)) => ~poisonous(x) - There are exactly two purple mushrooms.
(Ex)(Ey) mushroom(x) ^ purple(x) ^ mushroom(y) ^ purple(y) ^ ~(x=y) ^ (Az) (mushroom(z) ^ purple(z)) => ((x=z) v (y=z)) - Deb is not tall.
~tall(Deb) - X is above Y if X is on directly on top of Y or else there is a pile of one or more other objects directly on top of one another starting with X and ending with Y.
(Ax)(Ay) above(x,y) <=> (on(x,y) v (Ez) (on(x,z) ^ above(z,y)))
http://www.cs.wisc.edu/~dyer/cs540/notes/fopc.html
Tuesday, July 18, 2006
RTE 2 Preprocessed Dataset Format
Text'i cumlelere ayirmak icin MXTERMINATOR kullanilmis.
Her bir cumleyi parse etmek icin de MINIPAR kullanilmis.
Cumlelerdeki her bir "node" (noktalama isaretleri dahil) su attribute'lara sahip:
- node (e.g. 7)
- word (e.g. "declined")
- lemma (e.g. "decline")
- pos (e.g. v)
- relation (e.g. i) (bkz. MINIPAR Grammatical Categories)
- parent node (for the relation) (e.g. E3)
Parent Node iliskisi kullanilarak tree yapisi elde edilebilir.
RTE1 Dataset / Development: http://www.cs.biu.ac.il/~glikmao/dev2.zip
RTE1 Dataset / Test: http://www.cs.biu.ac.il/~glikmao/test.zip
RTE1 Dataset / Annotated: http://www.cs.biu.ac.il/~glikmao/annotated_test.zip
RTE 2 Dataset: http://ir-srv.cs.biu.ac.il:64080/RTE2/PASCAL/index.php?action=download
Her bir cumleyi parse etmek icin de MINIPAR kullanilmis.
Cumlelerdeki her bir "node" (noktalama isaretleri dahil) su attribute'lara sahip:
- node (e.g. 7)
- word (e.g. "declined")
- lemma (e.g. "decline")
- pos (e.g. v)
- relation (e.g. i) (bkz. MINIPAR Grammatical Categories)
- parent node (for the relation) (e.g. E3)
Parent Node iliskisi kullanilarak tree yapisi elde edilebilir.
RTE1 Dataset / Development: http://www.cs.biu.ac.il/~glikmao/dev2.zip
RTE1 Dataset / Test: http://www.cs.biu.ac.il/~glikmao/test.zip
RTE1 Dataset / Annotated: http://www.cs.biu.ac.il/~glikmao/annotated_test.zip
RTE 2 Dataset: http://ir-srv.cs.biu.ac.il:64080/RTE2/PASCAL/index.php?action=download
MINIPAR Grammatical Categories
The meanings of grammatical categories are explained as follows:
Det: Determiners
PreDet: Pre-determiners (search for PreDet in data/wndict.lsp for instances)
PostDet: Post-determiners (search for PostDet in data/wndict.lsp for instances)
NUM: numbers
C: Clauses
I: Inflectional Phrases
V: Verb and Verb Phrases
N: Noun and Noun Phrases
NN: noun-noun modifiers
P: Preposition and Preposition Phrases
PpSpec: Specifiers of Preposition Phrases (search for PpSpec
in data/wndict.lsp for instances)
A: Adjective/Adverbs
Have: have
Aux: Auxilary verbs, e.g. should, will, does, ...
Be: Different forms of be: is, am, were, be, ...
COMP: Complementizer
VBE: be used as a linking verb. E.g., I am hungry
V_N verbs with one argument (the subject), i.e., intransitive verbs
V_N_N verbs with two arguments, i.e., transitive verbs
V_N_I verbs taking small clause as complement
GRAMMATICAL RELATIONSHIPS
The following is a list of all the grammatical relationships in
Minipar. Search for (dep-type relation) in data/minipar.lsp for the
meaning of relation.
appo "ACME president, --appo-> P.W. Buckman"
aux "should <-aux-- resign"
be "is <-be-- sleeping"
c "that <-c-- John loves Mary"
comp1 first complement
det "the <-det `-- hat"
gen "Jane's <-gen-- uncle"
have "have <-have-- disappeared"
i the relationship between a C clause and its I clause
inv-aux inverted auxiliary: "Will <-inv-aux-- you stop it?
inv-be inverted be: "Is <-inv-be-- she sleeping"
inv-have inverted have: "Have <-inv-have-- you slept"
mod the relationship between a word and its adjunct modifier
pnmod post nominal modifier
p-spec specifier of prepositional phrases
pcomp-c clausal complement of prepositions
pcomp-n nominal complement of prepositions
post post determiner
pre pre determiner
pred predicate of a clause
rel relative clause
vrel passive verb modifier of nouns
wha, whn, whp: wh-elements at C-spec positions
obj object of verbs
obj2 second object of ditransitive verbs
subj subject of verbs
s surface subject
MINIPAR Homepage:
http://www.cs.ualberta.ca/~lindek/minipar.htm
(Information is from the README file of the program.)
Det: Determiners
PreDet: Pre-determiners (search for PreDet in data/wndict.lsp for instances)
PostDet: Post-determiners (search for PostDet in data/wndict.lsp for instances)
NUM: numbers
C: Clauses
I: Inflectional Phrases
V: Verb and Verb Phrases
N: Noun and Noun Phrases
NN: noun-noun modifiers
P: Preposition and Preposition Phrases
PpSpec: Specifiers of Preposition Phrases (search for PpSpec
in data/wndict.lsp for instances)
A: Adjective/Adverbs
Have: have
Aux: Auxilary verbs, e.g. should, will, does, ...
Be: Different forms of be: is, am, were, be, ...
COMP: Complementizer
VBE: be used as a linking verb. E.g., I am hungry
V_N verbs with one argument (the subject), i.e., intransitive verbs
V_N_N verbs with two arguments, i.e., transitive verbs
V_N_I verbs taking small clause as complement
GRAMMATICAL RELATIONSHIPS
The following is a list of all the grammatical relationships in
Minipar. Search for (dep-type relation) in data/minipar.lsp for the
meaning of relation.
appo "ACME president, --appo-> P.W. Buckman"
aux "should <-aux-- resign"
be "is <-be-- sleeping"
c "that <-c-- John loves Mary"
comp1 first complement
det "the <-det `-- hat"
gen "Jane's <-gen-- uncle"
have "have <-have-- disappeared"
i the relationship between a C clause and its I clause
inv-aux inverted auxiliary: "Will <-inv-aux-- you stop it?
inv-be inverted be: "Is <-inv-be-- she sleeping"
inv-have inverted have: "Have <-inv-have-- you slept"
mod the relationship between a word and its adjunct modifier
pnmod post nominal modifier
p-spec specifier of prepositional phrases
pcomp-c clausal complement of prepositions
pcomp-n nominal complement of prepositions
post post determiner
pre pre determiner
pred predicate of a clause
rel relative clause
vrel passive verb modifier of nouns
wha, whn, whp: wh-elements at C-spec positions
obj object of verbs
obj2 second object of ditransitive verbs
subj subject of verbs
s surface subject
MINIPAR Homepage:
http://www.cs.ualberta.ca/~lindek/minipar.htm
(Information is from the README file of the program.)
MINIPAR Parse Visualization Tool
MINIPAR is a broad-coverage parser for the English language. An
evaluation with the SUSANNE corpus shows that MINIPAR achieves about
88% precision and 80% recall with respect to dependency
relationships. MINIPAR is very efficient, on a Pentium II 300 with
128MB memory, it parses about 300 words per second.
MINIPAR Homepage:
http://www.cs.ualberta.ca/~lindek/minipar.htm
evaluation with the SUSANNE corpus shows that MINIPAR achieves about
88% precision and 80% recall with respect to dependency
relationships. MINIPAR is very efficient, on a Pentium II 300 with
128MB memory, it parses about 300 words per second.
MINIPAR Homepage:
http://www.cs.ualberta.ca/~lindek/minipar.htm
Pascal RTE 1 (More)
* System complexity and sophistication of inference did not correlate fully with performance.
* Naive lexically-based systems returned the best results.
For more information:
The PASCAL Recognising Textual Entailment Challenge: http://www.cs.biu.ac.il/~glikmao/rte05/dagan_et_al.pdf
* Naive lexically-based systems returned the best results.
For more information:
The PASCAL Recognising Textual Entailment Challenge: http://www.cs.biu.ac.il/~glikmao/rte05/dagan_et_al.pdf
Pascal RTE 1 Used Techniques
- word overlap between T and H, possibly including stemming, lemmatization,
part of speech tagging, and applying statistical word weighting such as idf.
(for example using simple decision tree trained by the development set: accuracy = 56%)
- consider relationships between words that may reflect entailment, based either on statistical methods or WordNet.
- measure degree of match between T and H, based on some distance criteria.
- few systems incorporated some form of "world knowledge."
- some of them applyied a logical prover.
- other techniques used are:
- probabilistic models
- probabilistic Machine Translation models
- supervised learning methods
- logical inference
- various specific scoring mechanisms
For more information:
The PASCAL Recognising Textual Entailment Challenge: http://www.cs.biu.ac.il/~glikmao/rte05/dagan_et_al.pdf
part of speech tagging, and applying statistical word weighting such as idf.
(for example using simple decision tree trained by the development set: accuracy = 56%)
- consider relationships between words that may reflect entailment, based either on statistical methods or WordNet.
- measure degree of match between T and H, based on some distance criteria.
- few systems incorporated some form of "world knowledge."
- some of them applyied a logical prover.
- other techniques used are:
- probabilistic models
- probabilistic Machine Translation models
- supervised learning methods
- logical inference
- various specific scoring mechanisms
For more information:
The PASCAL Recognising Textual Entailment Challenge: http://www.cs.biu.ac.il/~glikmao/rte05/dagan_et_al.pdf